Seiten-Zugriff durch Suchmaschinen regeln
Suchmaschinen erfassen die Webseiten der Universität in der Regel sehr schnell und sehr gründlich. Manchmal kann es sein, dass Sie nicht möchten, dass dies geschieht. Ein Beispiel sind für nur einen sehr kurzen Zeitraum relevante Informationen, die nicht noch nach Ablauf auffindbar sein sollen.
Für diesen Zweck gibt es die Möglichkeit Suchmaschinen zu signalisieren, dass eine Seite nicht erfasst werden soll.
Beachten Sie: Die meisten der großen Suchmaschinen wie Google oder Bing kooperieren und nehmen entsprechend gekennzeichnete Inhalte nicht in ihren Index auf. Jedoch gibt es andere Suchmaschinen, Archive oder Bots, welche diese Hinweise geflissentlich ignorieren und die Inhalte (unter Umständen ohne zeitliche Beschränkung) erfassen. Diese Einstellungen sind somit nicht geeignet um sensitive Inhalte zu schützen.
Vorgehen
Hinweis: Das hier beschriebene Vorgehen funktioniert nur für Seiten, welche die uzk2015-Extension verwenden. Ein TYPO3 ohne diese Extension verhält sich anders.
Dieses Vorgehen schreibt die Zeile <meta name="robots" content="NOINDEX,NOFOLLOW"> in den Quelltext Ihrer Seite. Das signalisiert Suchmaschinen und anderen Crawlern, dass die Seite nicht in den Index aufgenommen werden soll. Weiterhin wird auch signalisiert, dass den Links auf dieser Seite nicht gefolgt werden soll. Eine genauere Einstellung ist nicht möglich.
Um diese Einstellungen zu aktivieren, gehen Sie wie folgt vor:
- Loggen Sie sich im Backend Ihres TYPO3-Systems ein.
- Wählen Sie das Modul Seite.
- Im Seitenbaum machen Sie einen Rechtsklick auf die zu bearbeitende Seite und wählen "Edit" / "Bearbeiten".
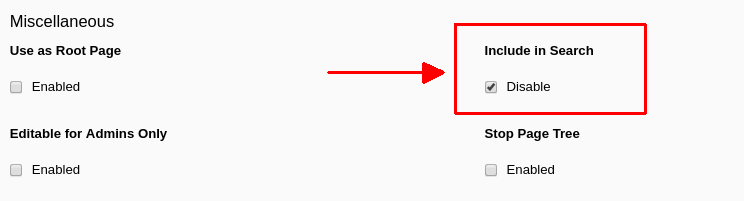
- Im Tab "Behaviour" / "Verhalten" finden Sie die Funktionsgruppe "Miscellaneous" / "Sonstige".
- Dort setzen Sie bei "Include in Search" / "In Indexsuche einbeziehen" ein Häkchen bei der Option "Disable" / "Deaktivieren".
- Speichern Sie.
- Erneuern Sie den Cache dieser einzelnen Seite.
Contact
If you have any questions or problems, please contact the ITCC-Helpdesk